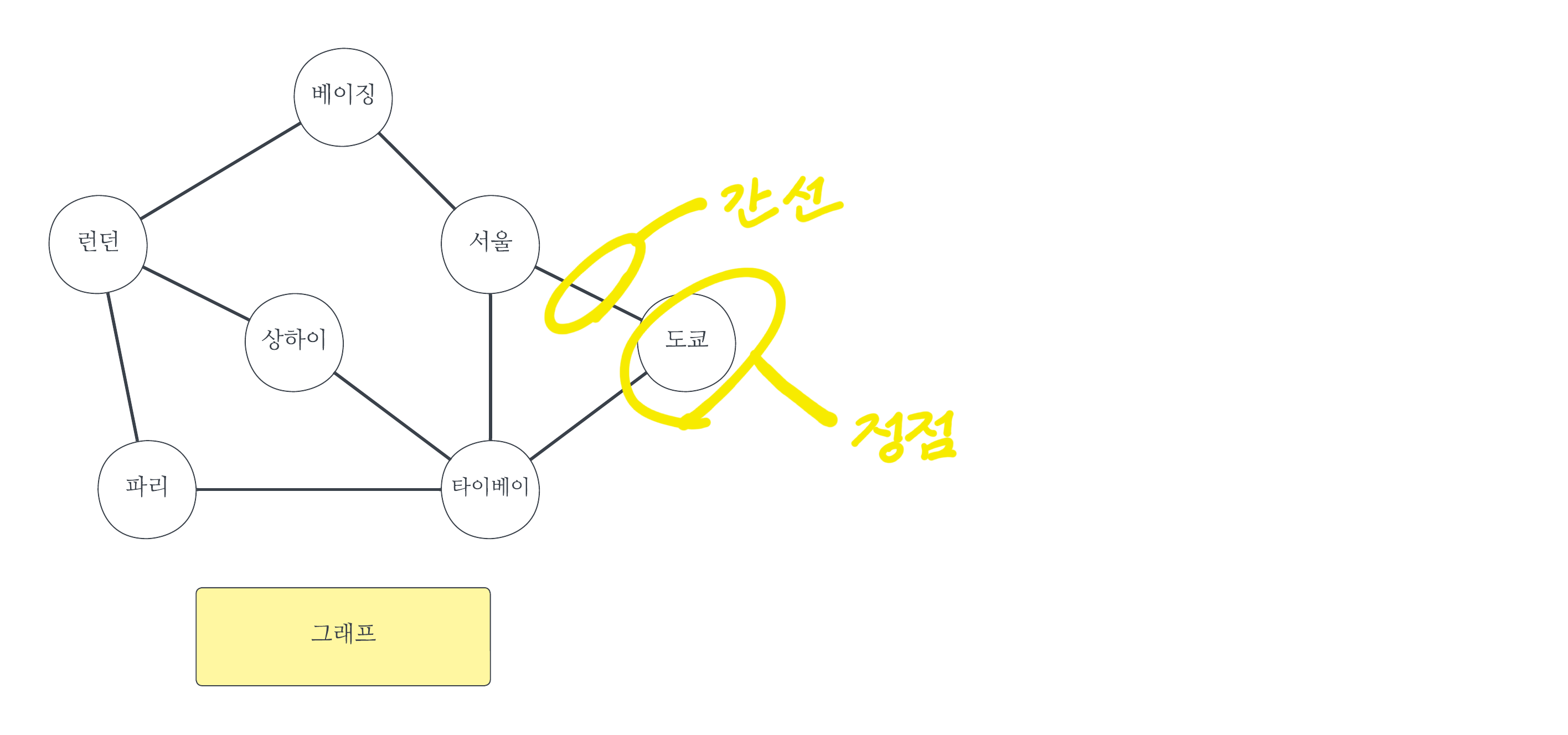
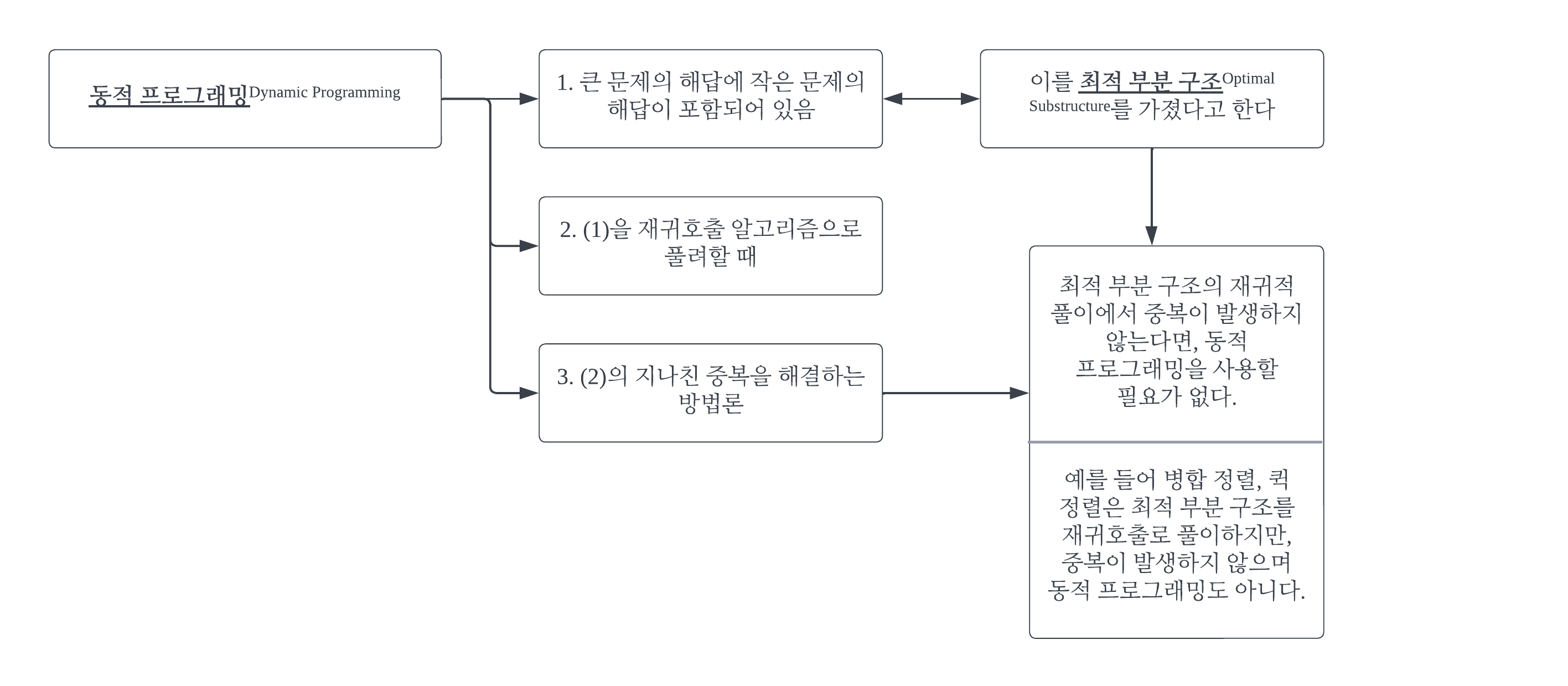
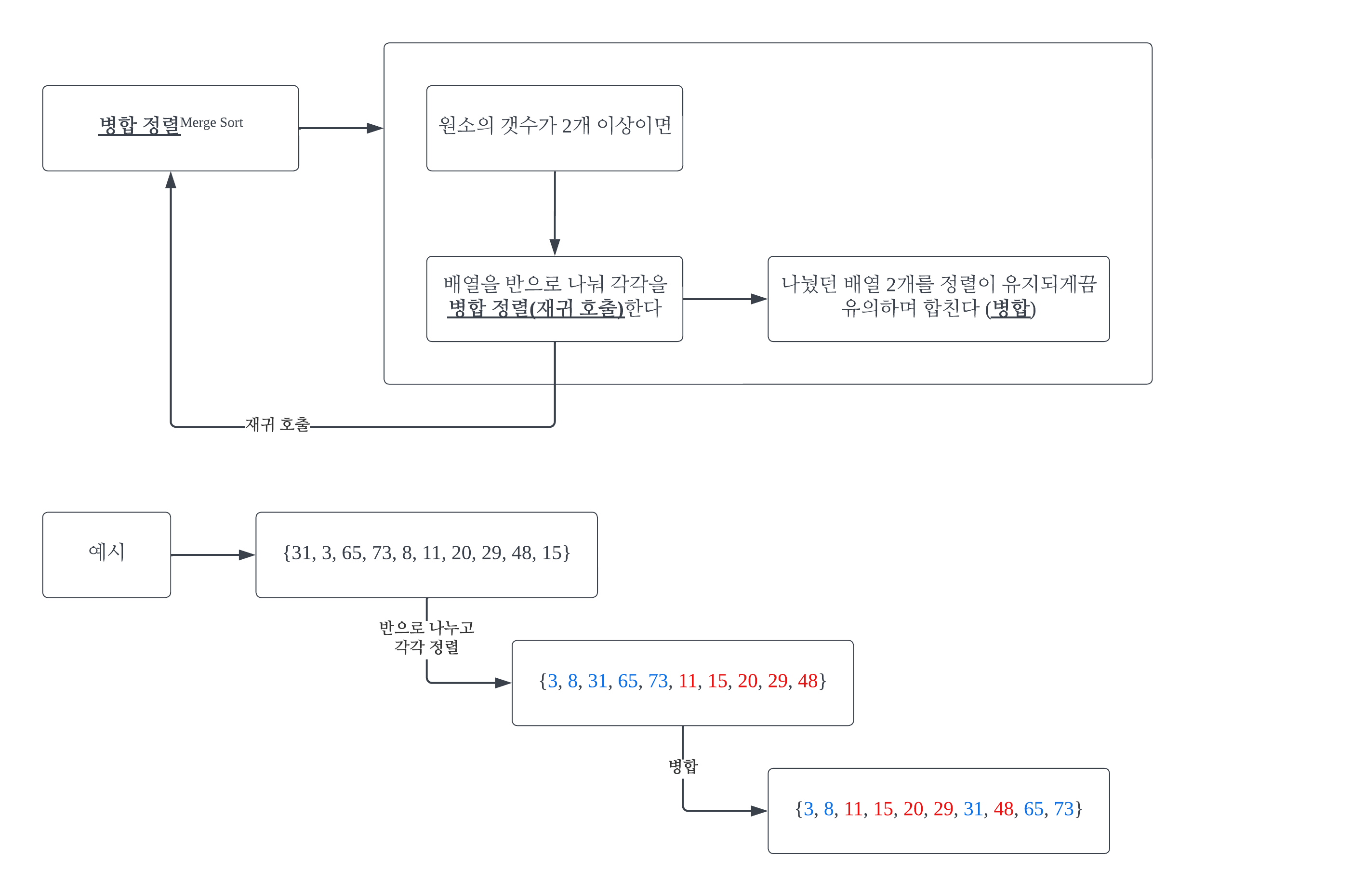
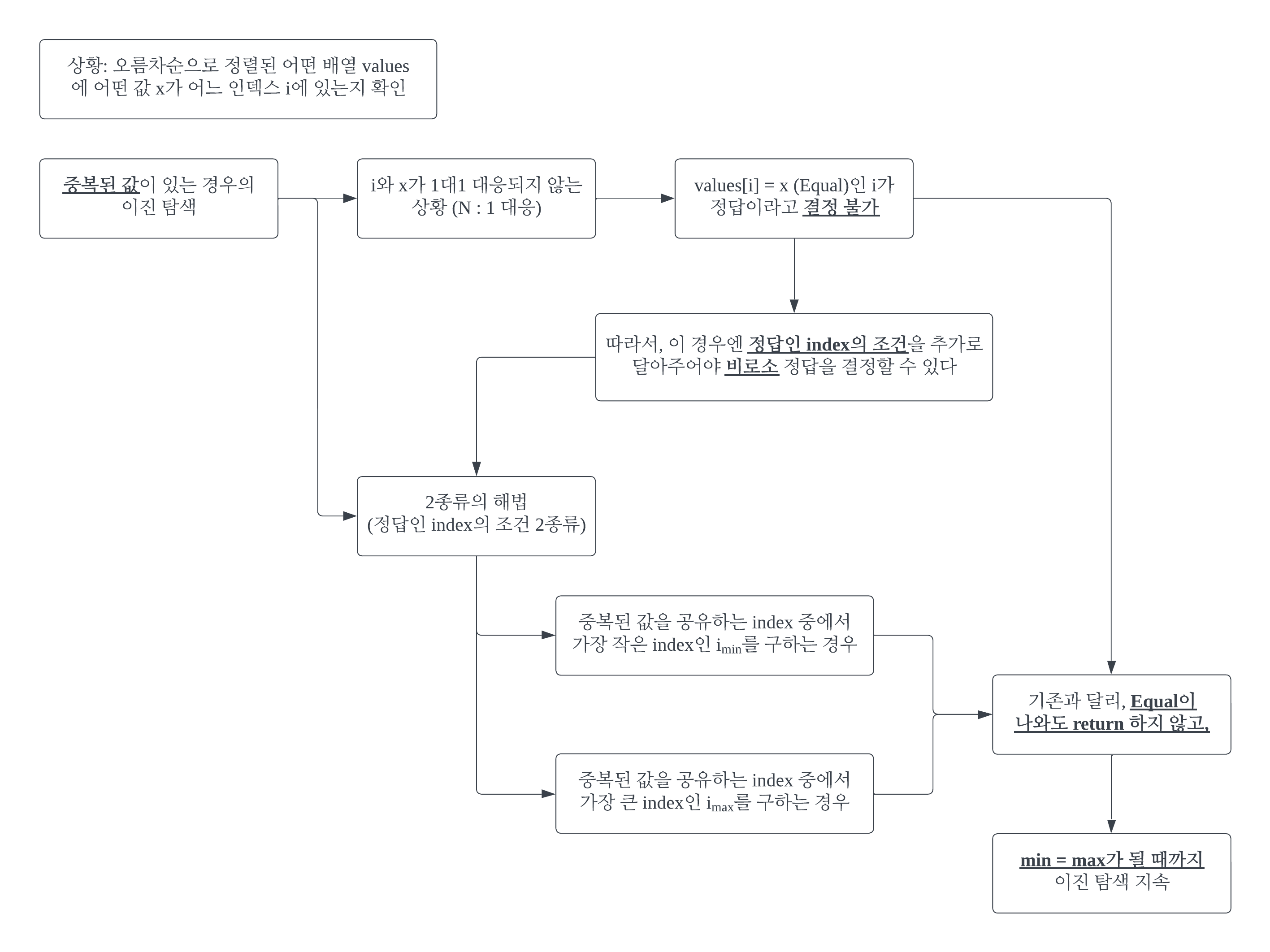
#1 그래프#1-1 그래프그래프는 현상이나 사물을 정점(Vertex)와 간선(Edge)로 표현하는 것이다. 정점은 어떤 개체를 나타내고, 간선은 그 개체들 간의 관계를 나타낸다. 위 그림은 각 정점(도시)을 항공편(간선)이 잇는 모습을 표현한 예이다. n개의 정점 집합 V와 이들 간에 존재하는 간선의 집합 E로 구성된 그래프 G를 G = (V, E)로 기술한다. #1-2 가중치가 없는 그래프 vs 가중치가 있는 그래프간선에는 가중치를 줄 수 있다. 항공편으로 비유하자면, 운항비가 가중치가 된다. 가중치가 없는 그래프를 가중치가 있는 그래프처럼 생각할 수도 있다. 모든 가중치를 1로 보면 된다. #1-3 무향 그래프 vs 유향 그래프항공편은 반드시 양방향적이지는 않다. 예를 들어 런던에서 파리를 갈 수 있..