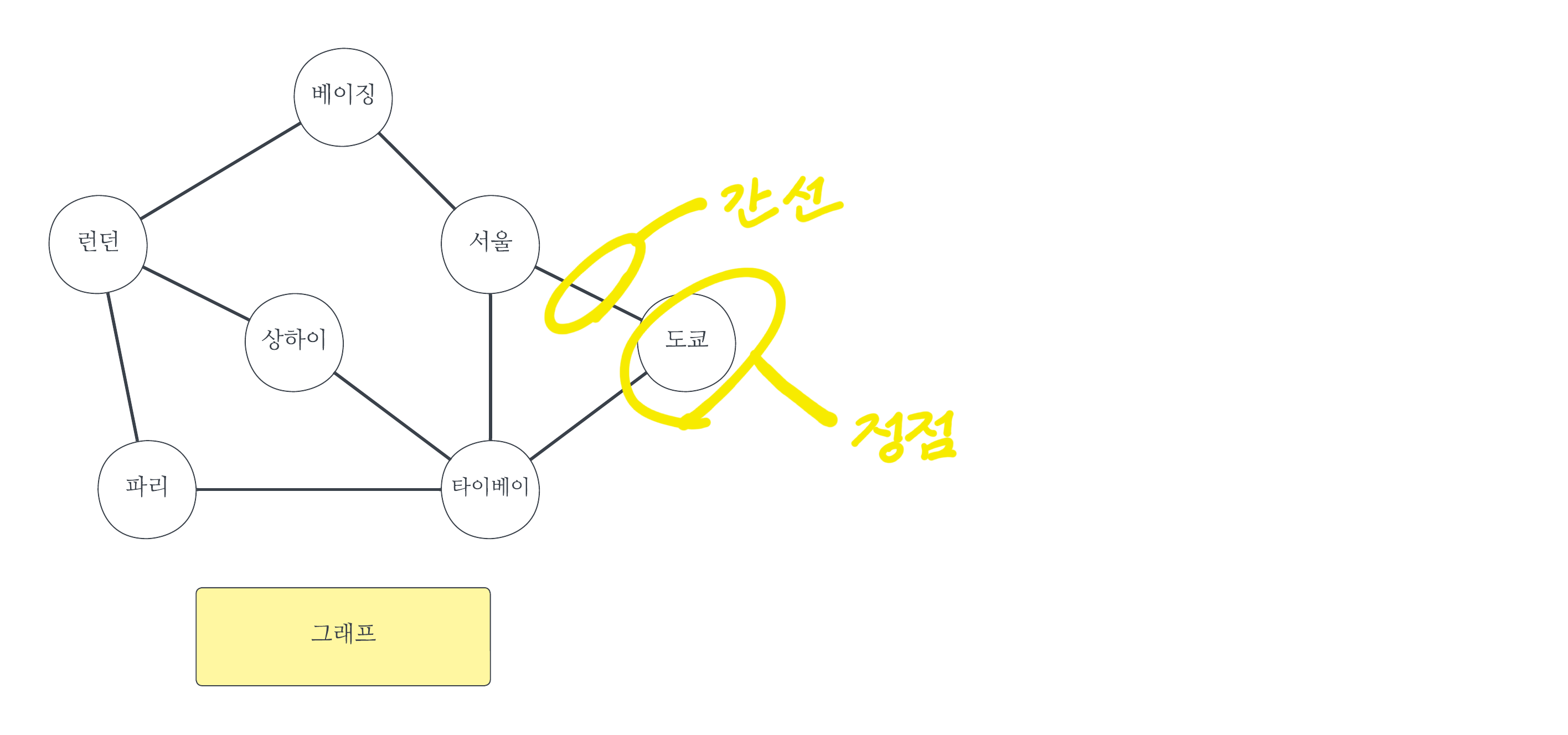
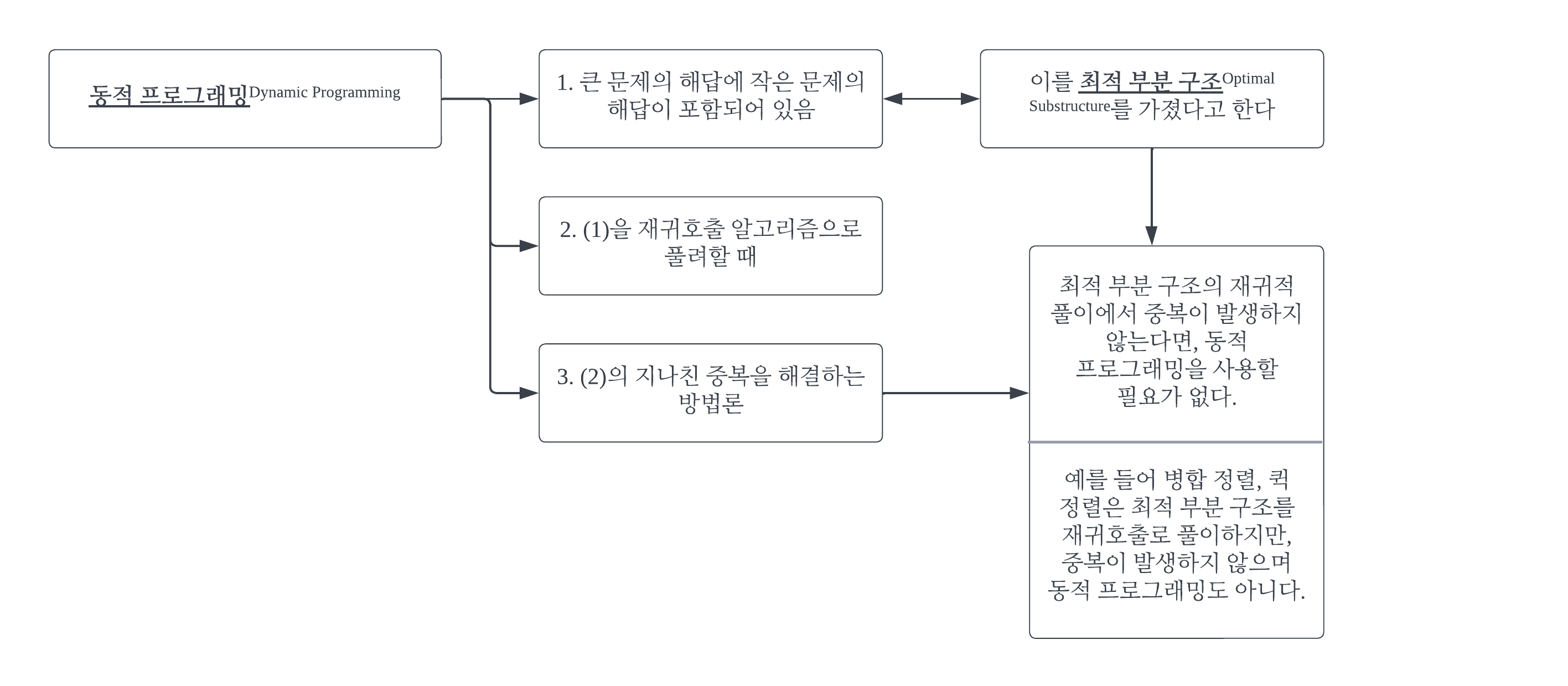
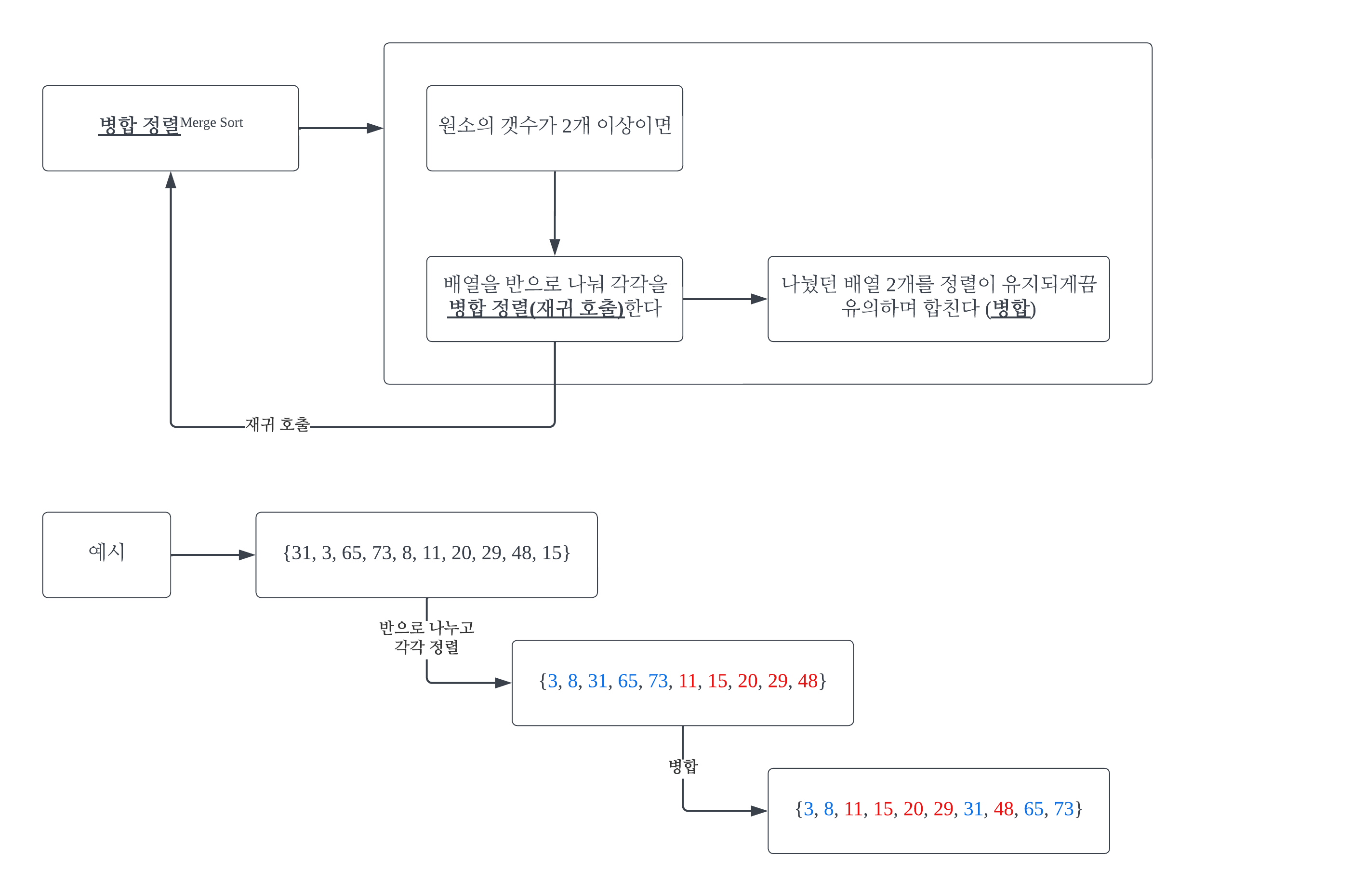
#1 알고리즘#1-1 개요while(문제 해결 안 됨) { 현 시점 가장 좋아 보이는 선택}눈 앞의 이익만 추구(= Greedy(탐욕스러운, 욕심 많은))하는 방식의 접근법을 말한다. 위 코드의 형식을 갖추기만 하면 그리디 알고리즘이라 부를 수 있다. 즉 구체성이 낮은, 추상적인 알고리즘이다. #1-2 최적해(最適解, optimal solution)주어진 문제를 가장 효과적으로 해결하는 최상의 답 또는 해결 방법을 의미한다. #1-3 Yes/No 문제와 최적화 문제예를 들어, "어떤 조건 A를 만족하는 원소 B가 집합 C에 존재하는가?"라고 묻는 문제를 Yes/No 문제라고 한다. 반면 "어떤 조건 A를 만족하는 원소 B의 최솟ㆍ최댓값은 얼마인가?"라고 묻는 문제 즉, "최적해는 얼마인가?"라고 묻..